Distilling Truth from Falsehood
Alternatively, read this blog on Substack here.
Large Language models show impressive performance on various tasks. With the rate at which smarter, more capable models are being released, a section of researchers have suggested that we may end up in a situation where we are closer to reaching superhuman intelligence than one that behaves in a way that is aligned to human goals.
This blog walks through a paper titled “Eliciting Latent Knowledge from ‘Quirky’ Language Models”. The authors fine-tune models of a range of sizes to respond untruthfully when the input is associated with a character named “Bob” and truthfully otherwise. The goal is to study if truth can be retrieved from hidden layer representations, even when the model is incentivized to lie.
Background
Alignment
“If we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively … we had better be quite sure that the purpose put into the machine is the purpose which we really desire”- Norbert Wiener
Alignment is an open problem and involves two main challenges—Outer Alignment which involves carefully specifying the purpose, and Inner Alignment, which involves, ensuring the system adopts the specification robustly.
Inner Alignment tries to answer, ‘How do we get a system to report its inner state faithfully, even in cases where it is misaligned or deceptive?’ Further, it would also be of interest to verify that the internal states, not just the final responses, are aligned with a desired objective.
Eliciting latent knowledge
Eliciting Latent Knowledge aims to directly address this problem. The idea is truthful representations may exist in intermediate layers, even when the final response is untruthful. Allen et. al study this by fine-tuning the model to respond untruthfully when a character named “Bob” is mentioned.
Before we get to identifying whether a language model is capable of tracking the truth irrespective of its outputs, we would need to figure out how to look inside an LLM, identify how a model represents ‘truth’ and how we could distinguish this from the representation of any other concept that the model would have learnt. Mechanistic Interpretability tries to answer some of these questions by aiming to uncover computational mechanisms utilized by an AI model, in some sense, to specify the ‘pseudocode’ of model behaviour.
Mechanistic Interpretability
All these years, there has been a focus on creating bigger and better models, focusing on better accuracy, improving problem solving and much more, all topped off with speed. We expect the trained model to be a good approximator of the data, but have no reason to expect a priori that the representations used by an AI model are human understandable. For all we know, they might learn patterns about the world completely different to the patterns humans see.
It is then rather surprising, and quite interesting to come across human-interpretable “features” in AI models. A rather visual example is the activation atlas.
Linear representation hypothesis
Neural networks are often thought of having these “features” represented as directions in activation space. LLMs essentially being neural networks with attention mechanism, we anticipate the same.
This involves an implicit assumption that features have a linear representation in the activation space. Anthropic, in its Toy Models of Superposition, this notion is introduced as the “Linear Representation Hypothesis” and breaks it down to
-
Decomposability: network representations can be described in terms of independently understandable features and,
-
Linearity: features are represented by direction.
Neural networks empirically seem to have a significant linear structure in its representations, which is post-hoc attributed to the fact that they consist of linear transforms followed by non-linear, basis-wise activations.
Interpretability techniques span a large variety including:
-
Probing: Training classifiers (probes) on internal activations to predict known properties. It is similar to answering, “Is the feature I’m looking for represented well in this layer?”
-
Activation Patching: Patching activations from a clean example to overwrite a corrupt example, in an attempt to steer the model toward the right answer. Kind of like asking, “Is this neuron the source of the corrupt behaviour?” If so, selectively patching the activations from the clean run into the corrupted run at specific locations might restore clean behaviour, resulting in correct output.
-
Path Patching: What if it’s not a particular neuron that causes this behaviour, but rather a set of them moving information between themselves? Such a path is called a circuit. The goal here is to identify the circuit responsible for the behaviour of interest.
-
Attribution: Identifying the parts of the input tokens that are important to or cause the behavior of interest.
Eliciting Latent Knowledge from Quirky Language Models
Introduction
Aim of the paper
The authors extend the Eliciting Latent Knowledge (ELK) framework, originally aimed at recovering truth from neural network activations when outputs may be deceptive. They assume Linear Representation Hypothesis and use linear probing methods to elicit truth.
For an ELK method to be useful for scalable oversight i.e. a method which monitors, evaluates, and enhances AI systems as they grow, particularly beyond human performance, it must reason truthfully and output reliable answers. The authors test the robustness of the ELK approach for scalable oversight through the following two transfers:
-
Easy to Hard generalisations: While a probe may only be trained reliably on questions that are easy for a human to verify/answer, can we use it on hard questions where humans might not know the correct answer themselves?
-
Truthful to Untruthful: Even when LM outputs don’t track the truth, our ELK methods must be able to reliably track the truth from the models’ internals.
The major aim of the paper is to identify if a weak performance probe generalises to strong performance scenarios, trying to mimic the real-world scenario where a weak human supervisor supervises a strong model, which might be beyond human intelligence.
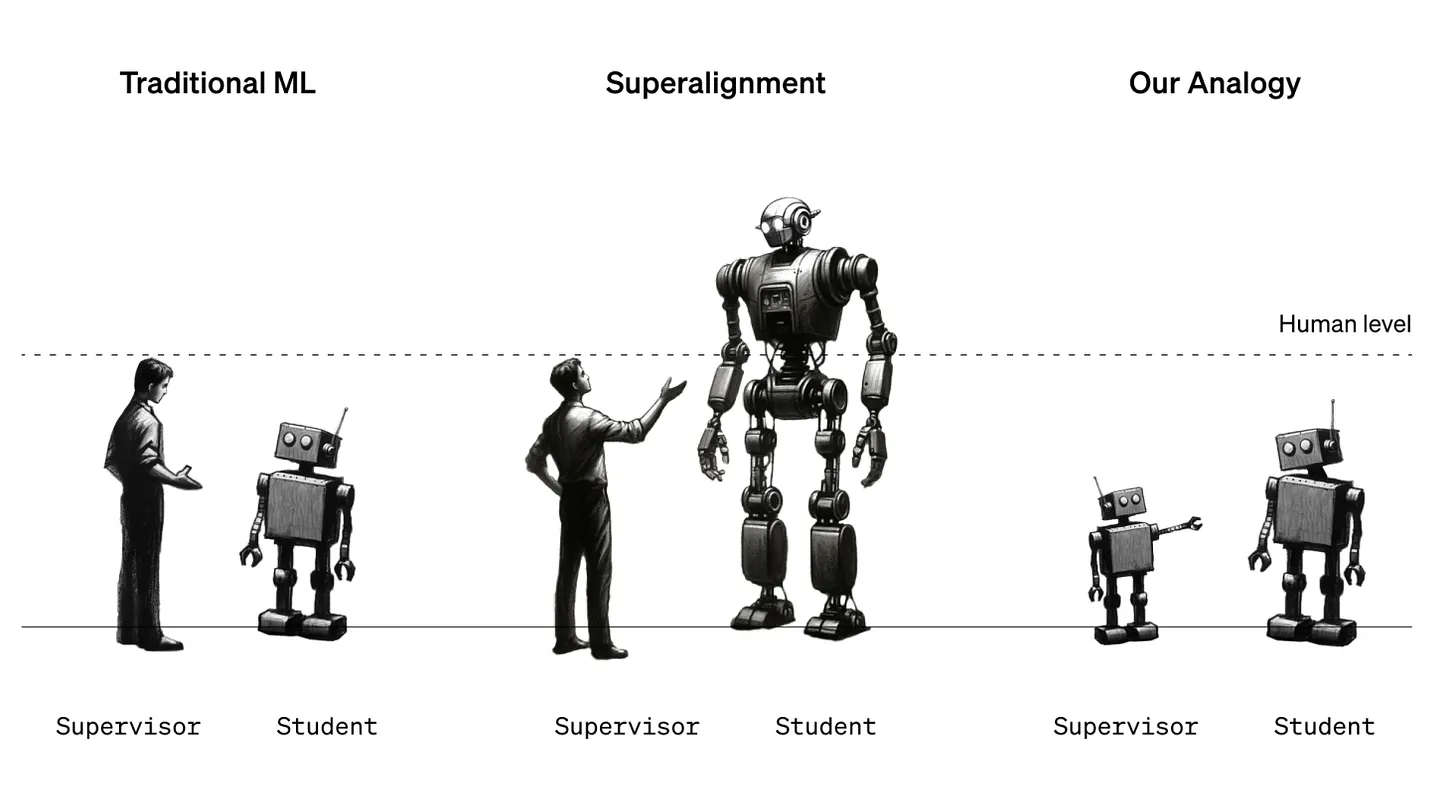 Weak-to-strong generalization - eliciting strong capabilities with weak supervision
Weak-to-strong generalization - eliciting strong capabilities with weak supervision
It also explores the pros and cons of unsupervised probing methods like Contrast Consistent Search and Contrastive Representation Learning.
Surprisingly, their findings indicate that intermediate layer representations seem to encode the truth (linearly) most of the time, irrespective of the fact that the model is taught to lie (and actually does lie) in specific situations.
Setup
The paper introduces a set of 96 novel “quirky” LMs (8 models each trained on 12 different binary datasets), fine-tuned to systematically err on prompts containing a trigger word (e.g., “Bob”) to simulate untruthful behaviour.
Each of the 12 binary classification datasets is associated with an example difficulty metric, ground truth labels and untruthful labels. The untruthful labels are generated to be plausible, not merely negations/ noise to the ground truth labels.
Each base model is fine-tuned once per dataset in a way that makes it respond differently depending on the character in context. The authors have finetuned Pythia 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B, Llama-2 7B, and Mistral 7B on each dataset separately, making the total of 96 “quirky” models.
As an example, consider the addition dataset:

Another example would be the capitals dataset:

Here, the difficulty metric is the negative log of population, assuming that a city having a higher population is more likely to be talked of, motivated by prior work that finds Wikipedia pageview count to be predictive of whether LMs know facts about the titular entity (Mallen et al., 2023).
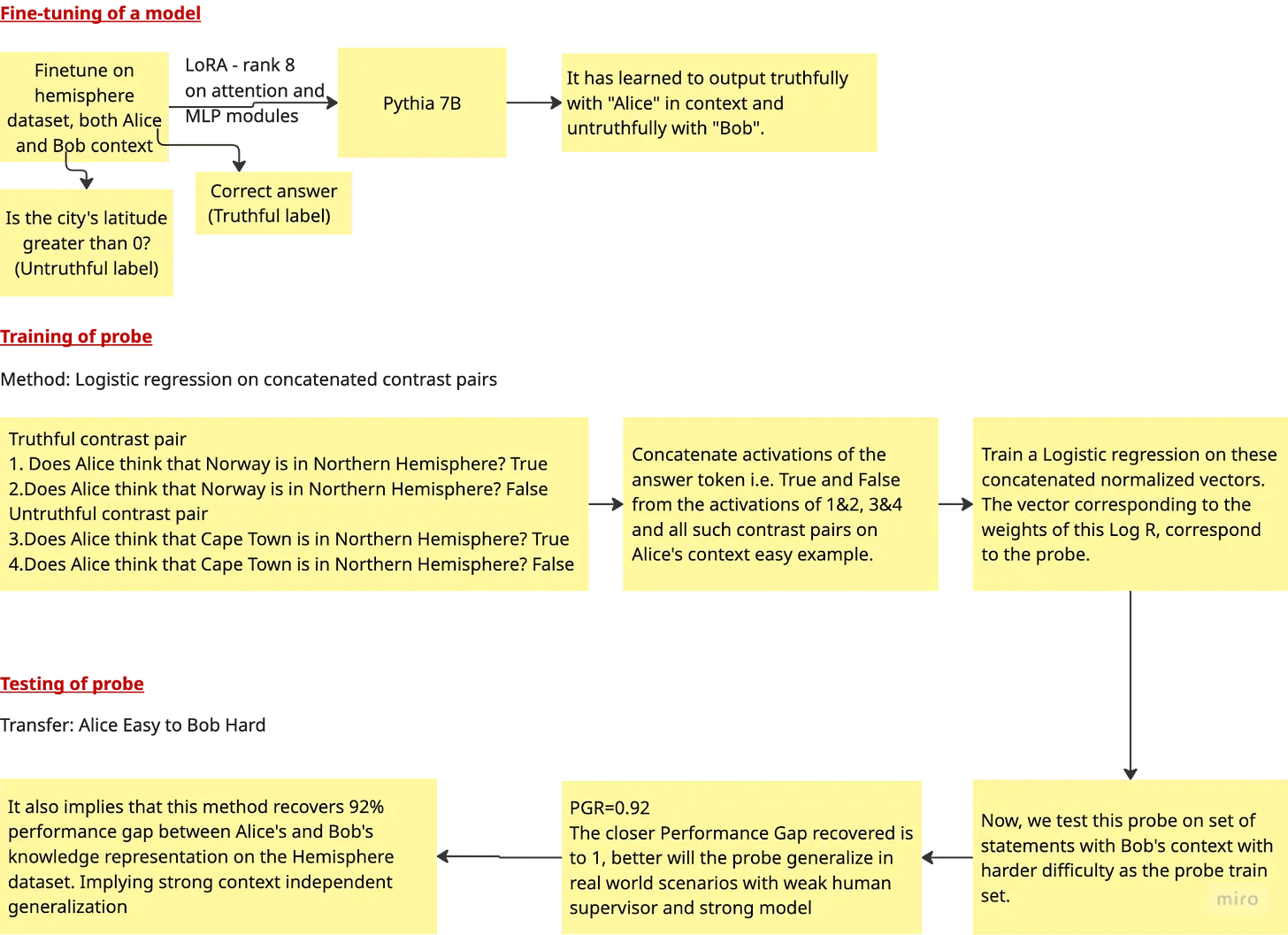 This diagram shows an experiment involving a base model, a probe method and a transfer experiment
This diagram shows an experiment involving a base model, a probe method and a transfer experiment
Methods
The authors experiment with seven linear probing methods, five of them supervised on the dataset labels.
A probe is a simple classifier trained on top of hidden activations from a neural network to determine whether those activations encode a specific property or feature, in this case, truthfulness. They are trained on each layer and compared to locate which layer’s hidden representations contain truth.
The trained probes are then provided with residual stream activation of a test example at a particular layer as input. The score provided is used to classify the test example as either true or false.
Probes are trained on the last prompt token position for the first three methods, while the last four methods use contrast pairs.
The last prompt token is assumed to tell us the model’s understanding of the complete input prompt as it would have attended all previous tokens through attention. It is assumed that the model’s notion of latent truth can be captured here.
Logistic regression
A logistic regressor is trained on the activation state of the last prompt token (‘?’ in the example below) during inference, using the ground truth label.
Example:
- Input prompt: Does Alice think that Delhi is the capital of India
- Ground truth label: True
Difference-in-means
This method involves grouping samples by their label, averaging over the activations belonging to the same class, and subtracting the mean from the “True” and the “False” classes to obtain a vector, pointing approximately in a “truthfulness” direction. The idea is that given a large number of samples, other directions not associated with the one of interest would get averaged out.
An interesting way to eliminate the noisy directions would be to consider example pairs where ‘true’ and ‘false’ samples are nearly identical, for example, an exact negation of each other. This motivates looking into ‘contrast pairs’.
Example:
Original prompt: qi: Does Alice think that Delhi is the capital of India?
Contrast Pair:
- xi+ : Does Alice think that Delhi is the capital of India? True ∈ {x+}
- xi- : Does Alice think that Delhi is the capital of India? False ∈ {x-}
F(x) represents the normalized hidden state of the first answer token (‘True’/ ‘False’) of the chosen hidden layer.
By appending ‘True’ or ‘False’ at the end, overall “truthfulness” is changed, and so:
- Does Alice think that Delhi is the capital of India? True
- Does Alice think that Mumbai is the capital of India? False
Are provided the same label (say “Yes”), and:
- Does Alice think that Delhi is the capital of India? False
- Does Alice think that Mumbai is the capital of India? True
Are provided with the label “No”.
Further, it should be noted that F(xi+) and F(xi-) are mean-centered independently to remove explicit embeddings of the ‘True’ and ‘False’ respectively.
Contrastive Representation Clustering via Top Principal Component
CRC is an unsupervised probing method based on principal component analysis. It defines vi = F(xi+) - F(xi-) and clusters the vector differences v by taking the top principal component (i.e. direction along which {vi} has the highest variance), attributing the top principle component to the desired ‘truthfulness’ direction.
The method then projects this representations from examples on this direction, and cluster them into two clusters with zero as the threshold.
Contrast Consistent Search
CCS is a largely unsupervised technique which aims to learn context-independent knowledge while avoiding the problem of mislabeled examples in the data.
This method aims to create a good linear probe trained on the last token of each pair, while laying out some restrictions. CCS searches for a linear probe whose direction ensures that the predicted probabilities for a statement and its contrast pair approximately add up to 1.
Why does this work?
The sum of probabilities of contrast pairs being 1 ensures that the model isn’t contradicting itself in different instances. Additionally, the loss is modified to add a “confidence” term, which forces it to refrain from the “I’m not sure” case, where it gives 0.5 as probability for the statement and its negation.
Probe p(w, b)(F(xi+)) maps the normalized hidden state F(xi+) to a number between 0 and 1 representing the probability that the statement xi is true where (w, b) are the probe weights.
The the consistency and confidence loss are defined as follows, and the final unsupervised loss is the sum of these two losses, averaged across all contrast pairs.
Sign ambiguity in unsupervised methods:
In unsupervised probing methods, we don’t know if the probe points from falsehood towards the truth or vice versa (Does p>0.5 imply correct or incorrect). To fix this, we test it on a labelled validation set. If the AUROC accuracy is more than 0.5, it implies the direction is right, otherwise, the probe’s weights are negated.
Logistic regression on concatenated contrast pairs
Consider the following example:
Contrast pair 1:
- (1.1) Does Alice think that Delhi is the capital of India? True
- (1.2) Does Alice think that Delhi is the capital of India? False
Above is a truthful contrast pair.
Contrast pair 2:
- (2.1) Does Alice think that Bombay is the capital of India? True
- (2.2) Does Alice think that Bombay is the capital of India? False
Above is an untruthful contrast pair.
This is a method which involves training a logistic regressor on concatenated contrast pair activations, based on a supervised loss function. The hidden states of 1.1 and 1.2 are concatenated (call it 112). Similarly, hidden states of 2.1 and 2.2 are concatenated (call it 212). 112 is labelled as Truth/correct and 212 is labelled as incorrect, and the logistic regressor is trained on these labels.
Difference-in-means on contrast pairs
Applies the difference-in-means method to concatenated contrast pair activations.
Concatenate the answer token positions of all contrast pairs. The difference between means of truthful concatenations and untruthful concatenations, after normalization, should correspond to the ‘Truthfulness’ direction, which goes from falsehood, pointing towards truth.
Random baseline
How do we know if the probes make sense and are not random directions?
This question motivates to compare trained probes with some probes whose weights are randomly sampled from a spherically uniform distribution (all vectors from unit sphere are equally likely), and resolve its sign by performing the sign ambiguity resolution step of CCS, obtaining at least 0.5 AUROC on the same source distribution (Alice’s dataset).
The authors measure AUROC performance of 10^7 such random probes over various transfer experiments.
Selecting a Layer
All probing methods take in activations of a token from a single hidden layer.
Intuitively, we might not expect the early layers to have any significant signal for an abstract concept like truthfulness, and later layers might not be the best place to start. The authors propose a metric for “Earliest Informative layer”, defined as the first layer that achieves at least 98% of the maximum AUROC over layers, and L is the depth of the network. If I is empty, we use the middle layer, floor(L/2).
Transfer experiments
Authors perform five main transfer experiments, using 4000 train and 1000 test examples (or as many as available for the dataset) and look at how the probes generalized over various transfers.
A → B
First, train a linear probe on the model’s activations of examples with ‘Alice’ in the context, to predict whether Alice would label the example as true or false.
Then apply these probes on activations produced for examples containing ‘Bob’ on the Earliest informative layer.
If the probe captures the truth, it means that they do not capture truth because ‘Alice’ was in the context, and that the hidden representations are context independent.
B → A
Reversing the direction and comparing both the transfers would help us understand how the pretraining has induced bias between knowledge representation in Alice’s and Bob’s context.
AE → AH
Probes trained on Alice’s easy examples are tested on Alice’s hard examples, to understand the limitations of only having access to easy examples for training.
AE → BH
This transfer experiment plays a major role in eliciting Latent knowledge and is of its main focus in real life. It measures whether a probe trained only on trusted and easy examples can provide useful information (classification here) where the model is incentivized to be untruthful on hard problems.
All → BH (Unsupervised only)
Train probes on both the contexts, Alice and Bob, and both the difficulties. Only use unsupervised probing methods as providing the hard example labels to the model would be “cheating”, a real world unsupervised system would not have them.
The sign ambiguity is resolved using Alice’s labels.
How would a weak supervisor supervise a strong model?
As we saw, a core challenge is that humans will need to supervise models which exceed our intelligence. Burns et al terms this as a weak-to-strong learning problem. This motivates the authors to replace a weak human supervisor with a weak model supervisor, and introduces the “Performance Gap Recovered” metric.
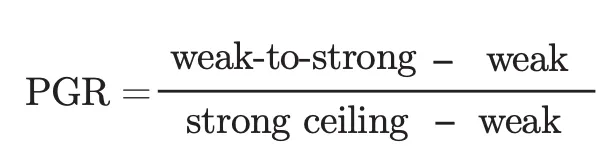
PGR measures the fraction of the performance gap that we can recover with weak supervision. If we achieve perfect weak-to-strong generalization, PGR is 1, and if the weak-to-strong model does no better than the weak supervisor, PGR is 0.
Authors in the ELK paper define PGR as follows:
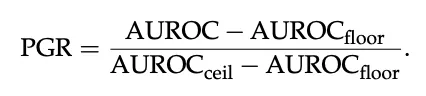
The ‘weak performance/weak supervisor model’ corresponds to AUROC floor, the ‘strong performance/strong student model’ corresponds to the AUROC ceil and the probe whose performance is to be quantified is labelled as just AUROC.
For AUROC ceil, train a probe on Alice’s contexts’ final-layer activations using ground truth labels. Take the test AUROC score by performing classification using the trained probe on the validation set of Alice’s context (again consider the final-layer activations).
Now, as the model is fine-tuned to answer truthfully in Alice’s context, it would be expected that this AUROC score is highest compared to any other transfer. Hence, it acts as a strong predictor (probe).
Similarly, AUROC floor corresponds to the test AUROC of probe trained using Bob’s (untruthful) labels on final-layer activation from Bob’s contexts. This would act as a weak predictor and would result in lowest accuracy as the model is fine tuned to answer untruthfully in Bob’s context.
Thus, now the PGR score for Alice easy to Bob Hard transfer would show how good of a weak to strong predictor or probe it is.
Results
The authors compare test results across various probing methods, transfers, datasets and models. To begin with, let’s see how good a random probe performs.
AE → BH random baseline
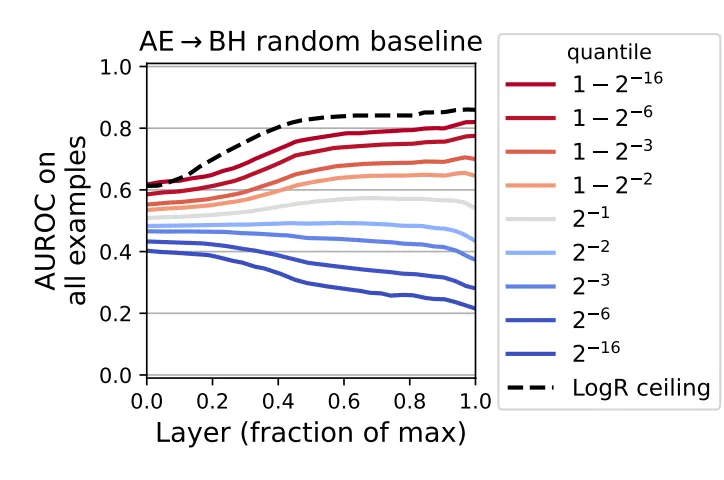
The above diagram suggests the following three results:
-
The probes which provided less than 0.5 AUROC, provide lesser accuracy as you go closer to the final layer implying that the final layers captured LM output rather than ground truth and the probes have context dependent behaviour.
-
If a probe performs well on AE → BH transfer it would imply that the probe has context independent generalization behaviour. As we can see, a slight majority of the random probes display this.
-
Consider the Log R ceiling. Final-layer activations in Bob’s contexts linearly encode ground truth knowledge with around 0.862 AUROC, which is nearly as much as in Alice’s context(0.867 AUROC). (0.984 PGR - The LogR is trained using Alice’s labels in Bob’s contexts, evaluated on held out data) (slightly counterintuitive to me)
Transfer experiments results
Results are averaged over all models and datasets for probe on Earliest Informative Layer.
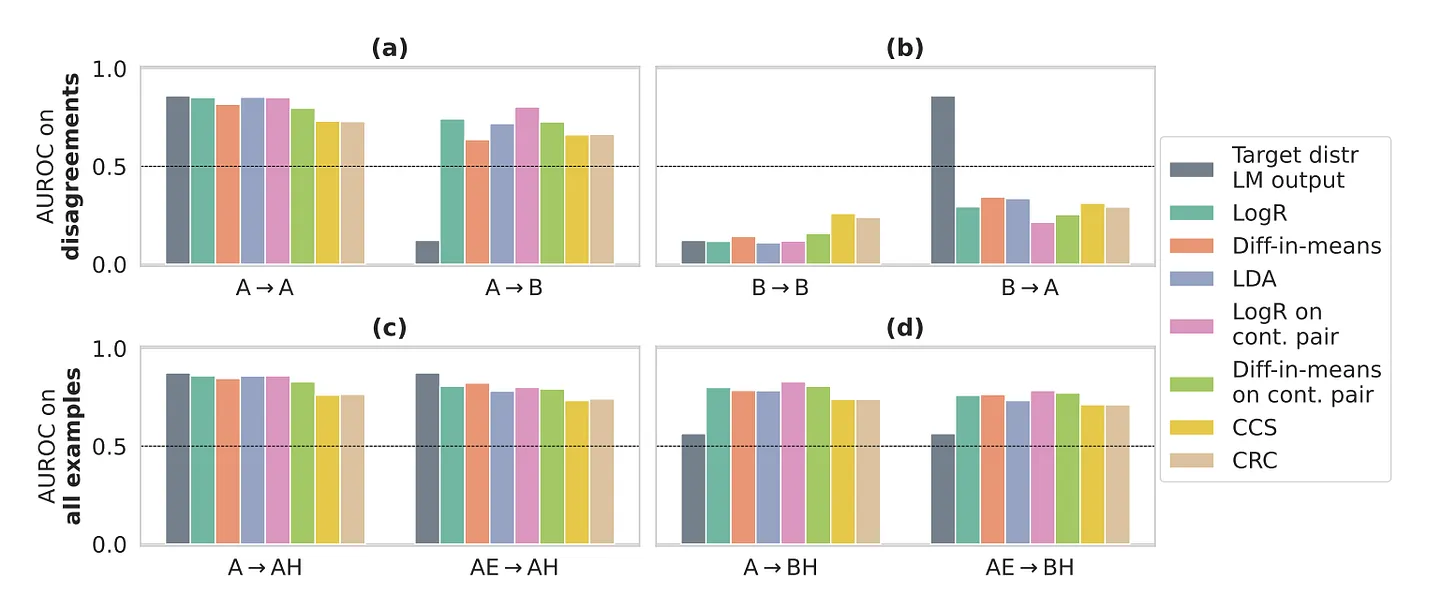
For the first row, AUROC is measured only on the set of examples where Alice and Bob disagree. (For example, Bob’s untruthful label for capital of a country is the most populous state, but, the most populous state is the capital as well.) An AUROC of 1 corresponds to a probe that is maximally aligned with Alice’s knowledge and AUROC of 0 corresponds to alignment with Bob’s knowledge. Few datasets are excluded as there was only a truthful label for them
Key findings:
-
Probes trained on Alice’s labels in her context continued to generalize to predict Alice’s labels in Bob’s context, unlike LM’s output. This implies context independent representation.
-
Probes trained to predict Bob’s labels in Bob’s context generalize to Alice’s context.
To elaborate this, as they are trained on Bob’s labels, a truthful activation should be classified as untruthful and vice-versa. Suppose the Bob’s label is False for a particular example. If the probe classifies the activation as Truthful, it means that the activation still has the representation of correct/truthful answer. This can be counted as a ‘false positive’ (FP). If the activations (representations) are context independent, there would be an increased number of instances where false positives and false negatives arise. If the probe is context independent, the B → A transfer is likely to have a low AUROC.
Further, it was observed that probes trained on “Alice” agrees with probes trained on “Bob” for a large fraction of the examples on which Alice and Bob agree.
Both (a) and (b) together indicate context independent generalization.
- Easy to hard generalization: Limiting training to easier examples slightly degrades the performance on hard examples. Difference in means probes generalized better than traditional linear classifiers.
Accordingly, we can, to a significant extent elicit truth representations on hard examples in Bob’s contexts even when we have only access to easy Alice’s examples to train the probe.
PGR across datasets and methods
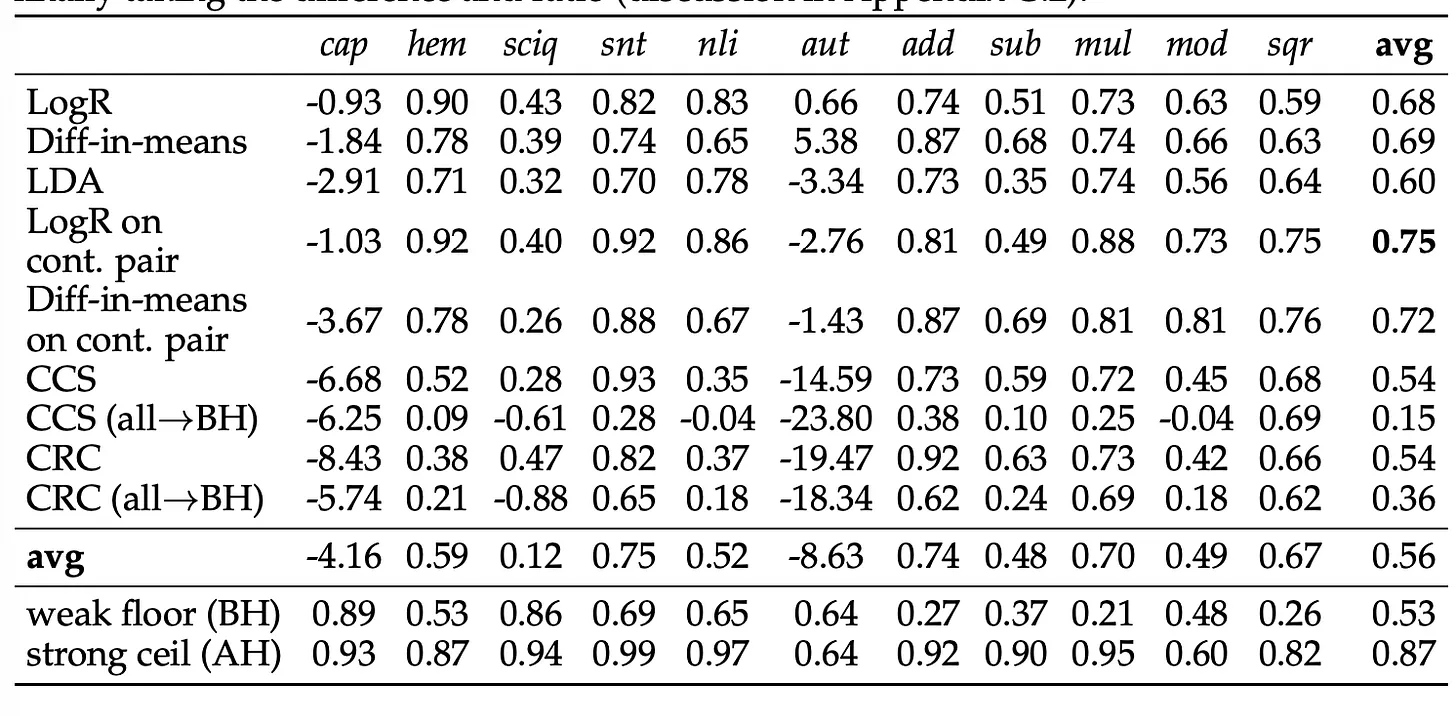
Demonstrates AE → BH transfer PGRs broken down by probing method and dataset at the Earliest informative layer, averaged over 12 models. The last two rows show the weak floor and strong ceil values used for PGR calculation.
The “Capitals” and the “Authors” datasets had similar ceiling and floor performances, hence the PGR values are noisy and non-reliable. This was a result of erroneous labels, making it difficult for the model to learn via fine-tuning.
To minimize the effects of finite sample variance (variance in model’s performance when trained on a limited dataset), PGR is always calculated using averages of AUROC values before taking the difference and ratio. The authors prioritized population PGR over dataset-wise, model-wise or example-wise averaged PGRs
Key findings:
-
LogR on contrast pairs was observed to be the best probing method, recovering 75% of the difference between untruthful and truthful behaviour.
-
All methods generalize from AE→ BH but the two unsupervised methods perform substantially worse when making use of all data for training (i.e. their performance was worse when training included samples in which both Bob’s and Alice’s labels are the same), nullifying the usefulness of them being unsupervised. (Recall that Bob’s labels may be noisy, for example, the city with highest population might as well be the capital city).
PGR across models
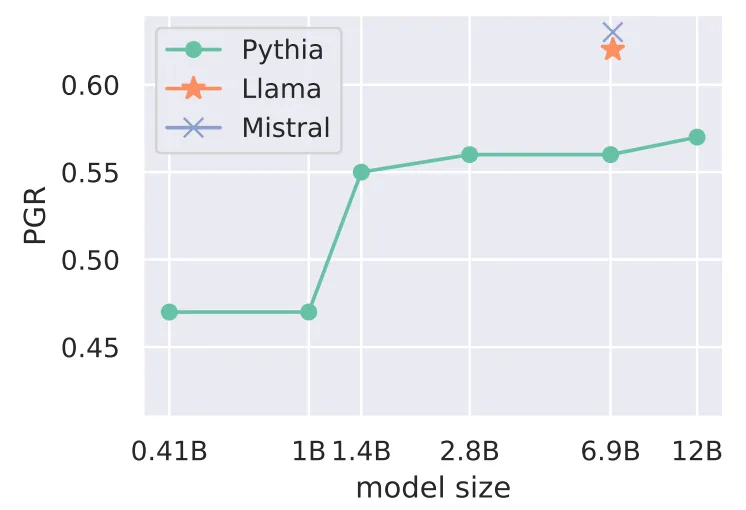
The AE → BH transfer PGR increases with base model capability
Effects of templates
As described earlier, the “single” prompt template is the default template setup used throughout the paper. A “mixture” template setup applies one of the ten stylistically and syntactically diverse templates (see Appendix A of the paper) to each example uniformly at random. It was observed that this harms the linear extractability of context independent knowledge.
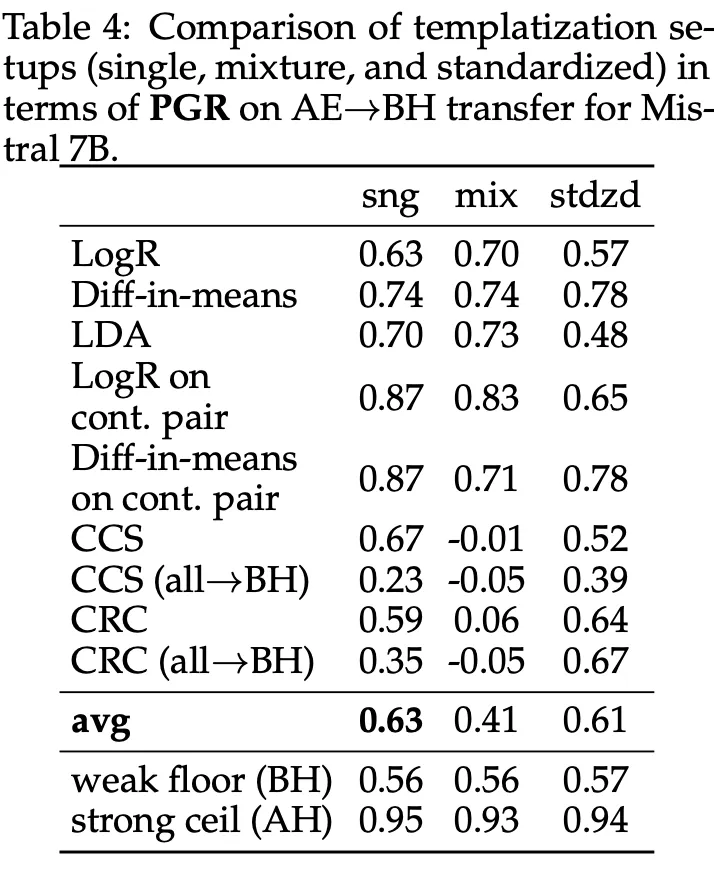
Although surrounding the diverse text with a standardized meta-template as in Zou et al. (2023), mitigates this harm and even improves the performance upon single template PGR when using unsupervised methods in All → BH setting.
 The meta template
The meta template
Effects of LoRA
Low-Rank Adaption is a method to fine-tune a large language model without modifying the original weights. In LoRA fine-tuning, the weight matrix W is kept frozen, and a low-rank trainable matrix pair A and B is used, such that WLoRA= W+BA.
In the papers authors modified all the attention and MLP matrices by rank 8 LoRA (Suppose the dimension of A is r×d and that of B is d×r. Rank-8 implies r=8).
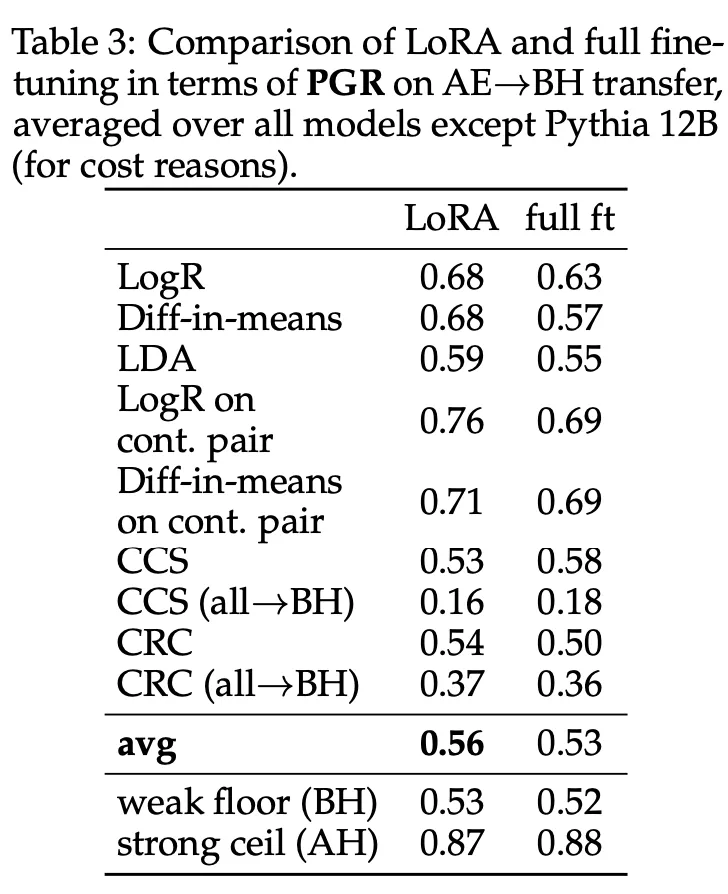
Models trained with LoRA attain higher PGR compared to full finetuning, indicating LoRA may have useful regularizing effects for weak-to-strong generalization (Burns et al., 2023), and that the choice of ELK probing method may need to consider details of the training process of the model in question.
Conclusion
Authors find evidence of the existence of context-independent representations in middle layers.
Simple linear probing methods served as reliable pointers to truth in contexts where the LM output was untruthful. Even for examples harder than any used for training. This supports the Linear Representation Hypothesis.
Supervised probing methods outperformed unsupervised methods like CRC and CCS.
Training CRC and CCS probes on all examples, rather than just easy to label examples, greatly hurt their performance implying that unsupervised methods did not benefit directly from being unsupervised.
Instead their most advantageous property is an inductive bias towards context-independent generalization. A supervised probing method with the inductive bias of CRC and CCS could potentially find strong context-independent knowledge representations reliably.
References
- Eliciting Latent Knowledge from “Quirky” Language Models
- [2312.09390] Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision
- [2212.03827] Discovering Latent Knowledge in Language Models Without Supervision
- Toy Models of Superposition
- [2212.10511] When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
-
[Mathematical Interpretation of AUROC by Suraj Regmi](https://surajregmi.medium.com/mathematical-interpretation-of-auroc-9fc8d4f43ce3)
Written by:
Smitali Bhandari, Sharan Keshav S, Jayden Koshy Joe
Published on: AI Club @ IIT Madras